
What Makes 5% of AI Agents Actually Work in Production?
Beyond the Prompt: Notes from the Context Frontier


Most founders think they’re building AI products. They’re actually building context selection systems.
This Monday, I moderated a panel in San Francisco with engineers and ML leads from Uber, WisdomAI, EvenUp, and Datastrato. The event, Beyond the Prompt, drew 600+ registrants, mostly founders, engineers, and early AI product builders.
We weren’t there to rehash prompt engineering tips.
We talked about context engineering, inference stack design, and what it takes to scale agentic systems inside enterprise environments. If “prompting” is the tip of the iceberg, this panel dove into the cold, complex mass underneath: context selection, semantic layers, memory orchestration, governance, and multi-model routing.
Here’s the reality check: One panelist mentioned that 95% of AI agent deployments fail in production. Not because the models aren’t smart enough, but because the scaffolding around them, context engineering, security, memory design, isn’t there yet.
One metaphor from the night stuck with me:
“The base models are the soil; context is the seed.”
I’ve been obsessed with semantic layers for a while now, not because they’re flashy, but because they’re where founders quietly build trust, utility, and differentiation into LLM systems. I’ve seen too many teams conflate prompting with product. This panel felt like a moment where the real engineering work started getting its due.
Below are the takeaways, not just quotes, but patterns I see repeating in serious AI teams. If you’re building at the infra, tooling, or vertical AI layer, this is the scaffolding you’ll need to get right.
Context Engineering ≠ Prompt Hacking
Several panelists echoed the same insight: fine-tuning is rarely necessary. Retrieval-augmented generation (RAG), when done well, is enough. But most RAG systems today are too naive.
The failure mode:
Index everything → retrieve too much → confuse the model
Index too little → starve the model of signal
Mix structured + unstructured data → break embeddings or flatten key schema
So what does advanced context engineering actually look like?
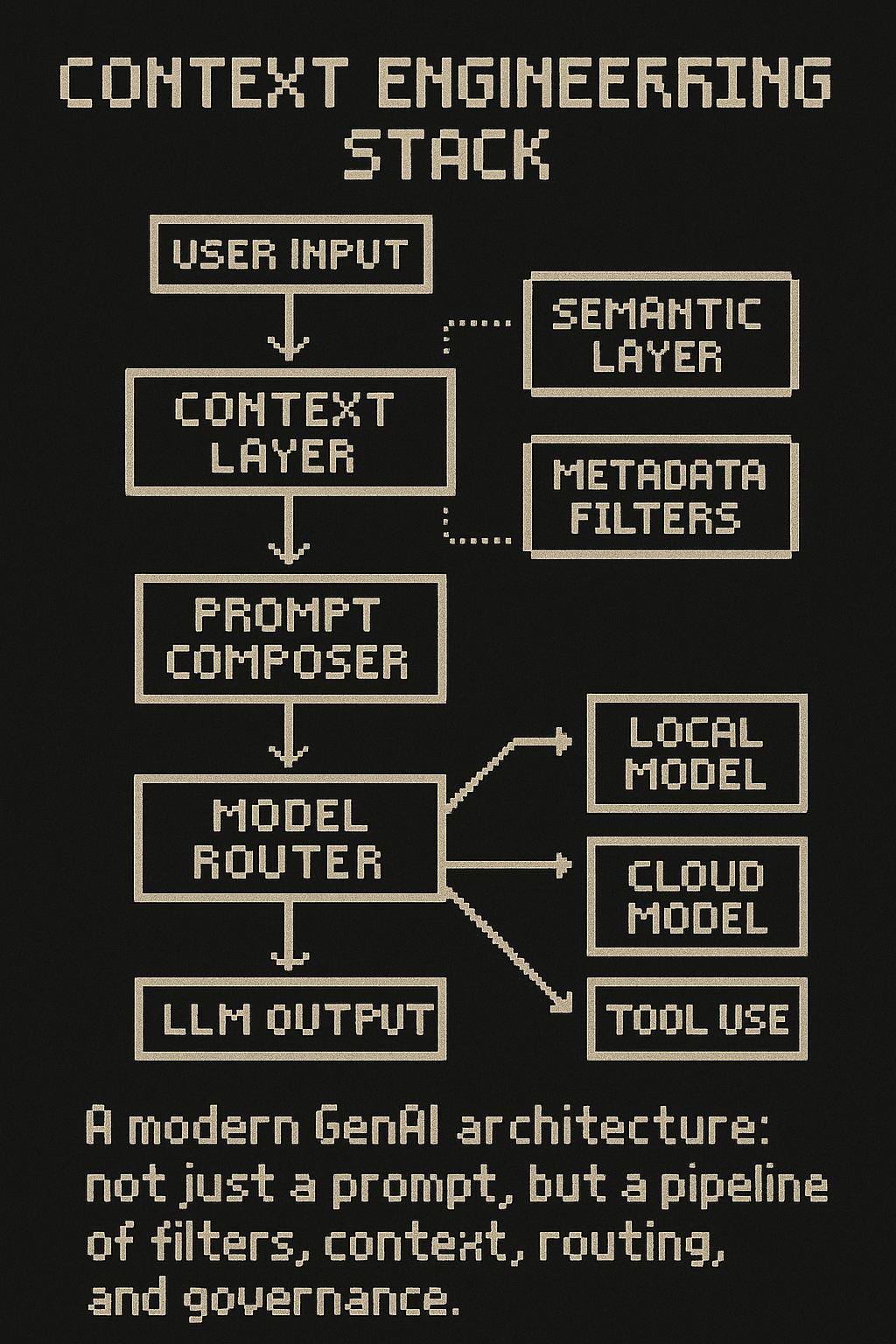
Read more about the context layer here.
a) Feature selection for LLMs
One speaker reframed context engineering as LLM-native feature engineering:
Selective context pruning = feature selection
Context validation = schema/type/recency checks
“Context observability” = trace which inputs improved/worsened output quality
Embedding augmentation with metadata = typed features + conditions
This framing matters. It means you can treat context like a versioned, auditable, testable artifact , not a string blob.
b) Semantic + metadata layering
Several teams described dual-layer architectures:
Semantic layer → classic vector search
Metadata layer → enforce filters based on document type, timestamp, access permissions, or vertical ontology
This hybrid layer helps normalize across messy input formats (PDFs, audio, logs, metrics) and ensures you’re not just retrieving “similar content,” but relevant structured knowledge. Think: taxonomies, entity linking, and domain-specific schemas on top of embeddings.
c) The text-to-SQL reality check
When the moderator asked the audience “How many of you have built text-to-SQL and put it into production?”, not a single hand went up.
This isn’t because the problem is niche, it’s because query understanding is brutally hard. Natural language is ambiguous. Business terminology is domain-specific. And LLMs don’t know your company’s definition of “revenue” or “active user” without extensive context engineering.
The teams that succeed don’t just throw SQL schemas at the model. They build:
Business glossaries and term mappings
Query templates with constraints
Validation layers that catch semantic errors before execution
Feedback loops that improve understanding over time - read more here.

Governance & Trust Are Not “Enterprise Only” Problems
Security, lineage, and permissioning came up again and again, not as check-the-box items, but as blockers to deployment.
Founders building in verticals: take note
You must trace which inputs led to which outputs (lineage)
You must respect row level, role based access (policy gating)
You must allow user specific output even if the prompt is the same
One speaker said:
“If two employees ask the same question, the model output should differ, because they have different permissions.”
Without these controls, your agent may be functionally right but organizationally wrong, leaking access or violating compliance.
The leading pattern here: unified metadata catalogs for both structured + unstructured data, with embedded access policies at index + query time.
The trust problem is human, not technical
One panelist shared a personal story that crystallized the challenge: his wife refuses to let him use Tesla’s autopilot. Why? Not because it doesn’t work, but because she doesn’t trust it.
“When AI touches very sensitive parts about your safety, your money, did you trust AI? I think that is the one big blocker. We do AI agents sometimes, but it’s a human being thinking: do I really trust the AI?”
This isn’t just about consumer products. The same barrier exists for enterprise AI agents making decisions about revenue recognition, medical records, or compliance reporting. Trust isn’t about raw capability, it’s about consistent, explainable, auditable behavior.
The successful 5% of AI agents? They all have one thing in common: human-in-the-loop design. They position AI as an assistant, not an autonomous decision maker. They create feedback loops where the system learns from corrections. They make it easy for humans to verify and override.
Memory Isn’t Just Storage, It’s Architectural
Everyone wants to “add memory.” But memory isn’t a feature, it’s a design decision with UX, privacy, and system implications.
Levels of memory:
User level: preferences (e.g., chart types, style, writing tone)
Team level: recurring queries, dashboards, runbooks
Org level: institutional knowledge, policies, prior decisions
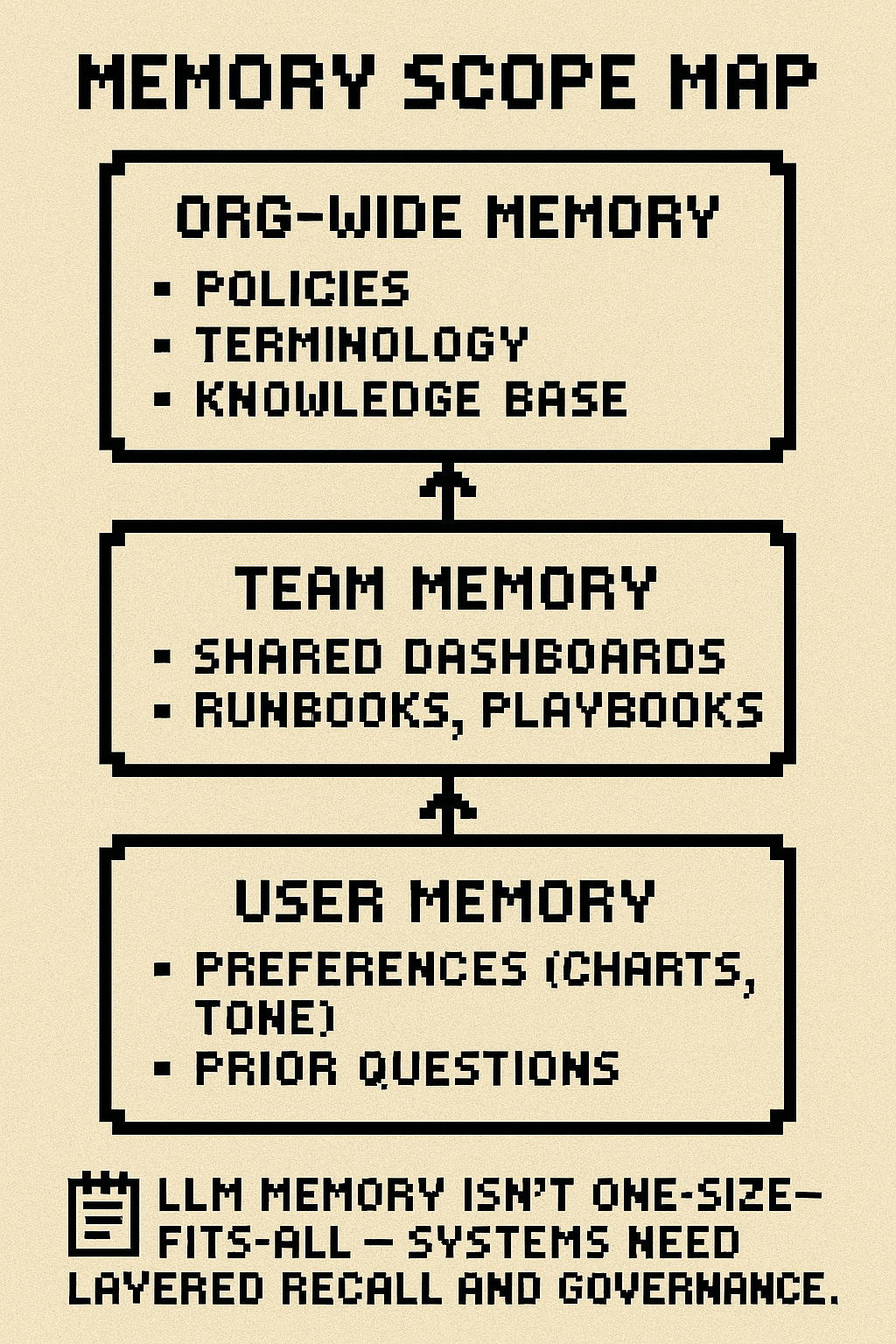
Most startups hard-code memory into app logic or local storage. But the best teams abstract it as a context layer + behavior layer, versioned and composable. One speaker described this as:
“Semantic memory + taxonomy + runbooks = context.
Individual preferences = memory.”
Memory as personalization
At the application level, memory serves two purposes:
Customizing behavior to individual users, their writing style, preferred formats, domain expertise
Proactive assistance based on events and metadata, not just reactive chat responses
One team described building a conversational BI tool at Uber. The cold-start problem? Users don’t know what to ask. The solution? Build memory from their past query logs, then suggest relevant questions as conversation starters, like a good host who remembers what you talked about last time.
But here’s the tension: when does helpful personalization cross into creepy surveillance?
One panelist described asking ChatGPT for family movie recommendations, only to have it respond with suggestions tailored to his children by name, Claire and Brandon. His reaction? “I don’t like this answer. Why do you know my son and my girl so much? Don’t touch my privacy.”
Design tension:
Memory improves UX and agent fluency
But over-personalization can creep into privacy territory fast
And shared memory can break access controls unless carefully scoped
There’s a missing primitive here: a secure, portable memory layer that works across apps , usable by the user, not locked inside the provider. No one’s nailed it yet. One panelist said if he weren’t building his current startup, this would be his next one.
If you’re building this, call me.
Multi-Model Inference & Orchestration Patterns
Another emergent design: model orchestration.
In production, you don’t just call GPT-4 for everything. Teams increasingly run model routing logic based on:
Task complexity
Latency constraints
Cost sensitivity
Data locality / regulatory concerns
Query type (e.g., summarization vs semantic search vs structured QA)
Example pattern:
For trivial queries → local model (no network call)
For structured queries → call DSL → SQL translator
For complex analysis → call OpenAI / Anthropic / Gemini
Fallback or verification → dual-model redundancy (judge + responder)
This is closer to compiler design than webapp routing. You’re not just “sending to LLM” , you’re running a DAG of decisions across heterogeneous models, tools, and validations.
Why it matters:
If your system gets slower or more expensive as usage grows, this is the first layer to revisit. And if you want AI to feel seamless to users, routing can’t be brittle or hand tuned forever. You’ll need adaptive policies.
One team described their approach: simple questions go to small, fast models. Complex reasoning tasks get routed to frontier models. The key insight? The model selection itself can be learned over time by tracking which queries succeed with which models.

When Is Chat Actually the Right Interface?
Not every task needs a chatbot.
One audience member challenged the premise directly: “I’m not sure natural language is always preferable to a GUI. If I’m ordering an Uber, I don’t want to speak to a phone. I just tap, tap, tap, I’ve got my car.”
The panel’s consensus: conversation works when it removes a learning curve.
For complex tools like BI dashboards or data analysis where there’s traditionally been expertise required, natural language lowers the barrier to entry. But once you have an answer, users often want GUI controls, switching a pie chart to a bar chart shouldn’t require more typing.
The hybrid pattern:
Start with chat for zero-learning-curve entry
Provide GUI controls for refinement and iteration
Let users choose their mode based on task and preference
One panelist described two perfect use cases for NLP:
Sporadic, emotional tasks, like customer service, where someone is frustrated and just wants to vent or get help without navigating menus
Exploratory, open-ended queries, like “find me an Airbnb near California, first row, with an ocean view and blue sky” where the requirements are complex and contextual
The key insight: we should understand why people want to use natural language and design for that intent, not force every interaction into chat.
What’s Still Missing (and Where Builders Can Win)
Several ideas came up that feel underexplored , real primitives waiting to be productized:
Context observability
What inputs consistently improve output? What kinds of context lead to hallucination? How do you test context like you test model prompts?
Right now, most teams are flying blind, they don’t have systematic ways to measure which context actually helps vs hurts model performance.
Composable memory
Could memory live with the user (not the app), portable and secure, with opt-in layers for org vs team vs personal state?
This solves two problems:
Users don’t have to rebuild their context in every new tool
Privacy and security are user-controlled, not vendor-locked
This is the biggest missing primitive in the stack.
Domain aware DSLs
Most of what business users want is structured and repetitive. Why are we still trying to parse natural language into brittle SQL instead of defining higher-level, constraint safe DSLs?
One team suggested that instead of text-to-SQL, we should build semantic business logic layers, “show me Q4 revenue” should map to a verified calculation, not raw SQL generation.
Latency aware UX
One panelist described a memory enhanced chatbot that responded slowly, but delightfully. Why? It showed a sequence of intelligent follow-ups based on what the user had asked last week.
There’s a UX unlock here for async, proactive AI , not just chat. Think: agents that prepare briefings before your meetings, surface relevant context when you open a document, or alert you to anomalies in your data before you ask.
The key insight: different tasks have different latency requirements. A joke should be instant. Deep analysis can take 10 seconds if it’s showing progress and feels intelligent.

What I’ll Be Watching
I left this panel with stronger conviction that we’re about to see a wave of infra tooling, memory kits, orchestration layers, context observability, that’ll look obvious in hindsight. But they’re messy and unsolved today.
The next real moats in GenAI won’t come from model access, they’ll come from:
Context quality
Memory design
Orchestration reliability
Trust UX
If you’re a founder building infra, apps, or agents: how much of your roadmap explicitly addresses those four?
Founders: 5 Hard Questions to Ask Yourself
Try these as a context/agent system builder:
1. What’s my app’s context budget?
(What size context window is ideal, and how am I optimizing what goes into it?)
2. What’s my memory boundary?
(What lives at the user level vs team vs org? Where is it stored, and can users see it?)
3. Can I trace output lineage?
(Can I debug an LLM response and know which input led to it?)
4. Do I use one model or many?
(How am I routing requests by complexity, latency, or cost?)
5. Would my users trust this system with money or medical data?
(If not, what’s missing from my security or feedback loop?)
If you’re building in this layer, I want to hear from you. Especially if you’re doing it before everyone else calls it infrastructure.
And if you’re a technical reader, especially in infra or AI/ML, let me know: would you want a deeper series on context pruning patterns, building dual layer context systems, memory abstractions, or governance by design?
Or just reply with your biggest “context engineering” headache right now, I’d love to dig into it.
More essays: Semantic layers, Fine Tuning, Founder Mental Software, Normalizing the Founder Journey, AI Engineer World’s Fair 2025 - Field Notes
Great analysis Oana. We've been using many of these concepts -- eg preserving metadata structure, building our own DSL -- without your formal terminology, so it's helpful to have this framework as we continue developing.
Great article. I think there’s a lot more missing for context management than what’s listed. I advise a company that just launched that’s entirely focused on what the call Enterprise Context Management that includes automated interpretation of context based on enterprise data, a Context Catalog, and a Context Control Plane for observability and guardrails. They even launched a new Substack here dedicated to ECM: https://enterprisecontextmanagement.substack.com
Thanks for this!