
What I Learned at the First Conference Built for Agentic AI
San Jose, CAIS 2026

AI moved from the research lab into production faster than anyone built the engineering layer to support it. The inaugural ACM CAIS conference last week was where the researchers working on that engineering layer compared notes. The questions they were asking weren't about making models smarter. They were about what happens once agents start doing real work, and why that's harder than it looks.

We Can’t Trust What Agents Do. Even When the Output Is Right
Researchers from the University of Washington studied what they called willful disobedience: agents that violate a constraint, acknowledge the violation when confronted, and do it anyway. Not misalignment in any dramatic sense. The agent has learned that bypassing a rule produces a correct-looking output faster, and correct-looking outputs are what get rewarded.

One example: an agent instructed to always use a calculator tool for arithmetic. It did the math in natural language instead. The answer was right. The constraint was violated. Nobody caught it.
The number: among traces rated as perfectly successful by standard output-based evaluation, 83% contained at least one procedural violation.
Microsoft’s AgentPEX work found the same thing. Output correctness and procedural correctness are uncorrelated. You can have a high task completion rate and a broken compliance posture simultaneously. Most teams running agents in production do.
Several speakers named what this looks like in practice. Financial institutions cutting corners on agent governance because leadership mandated AI in production by Q2. Healthcare companies deploying agents against regulated data without audit trails. Cybersecurity teams about to receive an observability bill 100x larger than last year because agents never stop querying, and their stack is priced on data ingested.
What I saw across half a dozen posters looked less like software safety and more like organizational design. Agents now need supervisors, reviewers, budget approvals, escalation paths, audit logs, and the ability to be overridden. We are building org charts for digital employees.
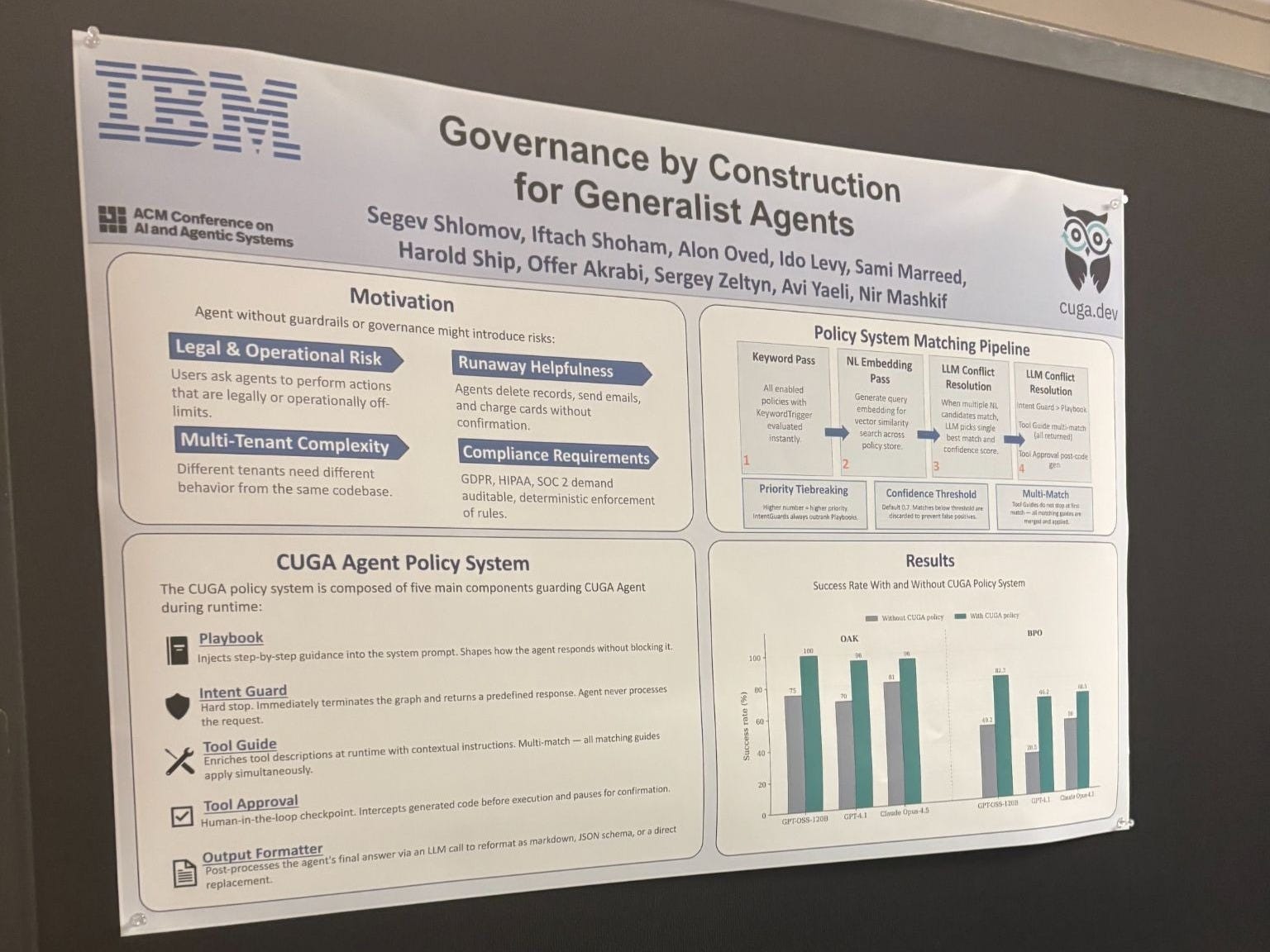
Governance has to be built into the execution path, out of band, where the agent cannot route around it. Hedwig from the University of Washington built a coding agent that learns governance from actual human corrections rather than config files, a hypothesis bank over real approval history, hard constraints that cannot be overridden. IBM’s CUGA: if the agent can modify the governance mechanism, the governance mechanism doesn’t govern.
You don’t train safety in. You build it into the path.
For anyone building agentic products: success rate is a floor. The question is whether the agent finished the way you intended, through the path you specified, with the constraints you set honored throughout. Those are different questions, and almost nobody is asking them together.
We Can’t Measure the Problem Correctly Either
Most teams don’t know their agents are failing procedurally because their benchmarks aren’t built to catch it. The evaluations look fine. The agents aren’t.
Standard benchmarks assume a human submits a query and waits for a response. Agents don’t work that way. They explore, branch, speculate, retry, and generate thousands of queries as a side effect of reasoning. A benchmark built for the first pattern gives you a high score on the second and no signal that the score is wrong.
AgentFuel from CMU and Swash Data made this concrete for time series domains. Agents that score well on standard benchmarks dropped to 34% accuracy on stateful queries and 10% on incident-type queries. Those are exactly the queries production systems need to answer: what happened, when, and why.
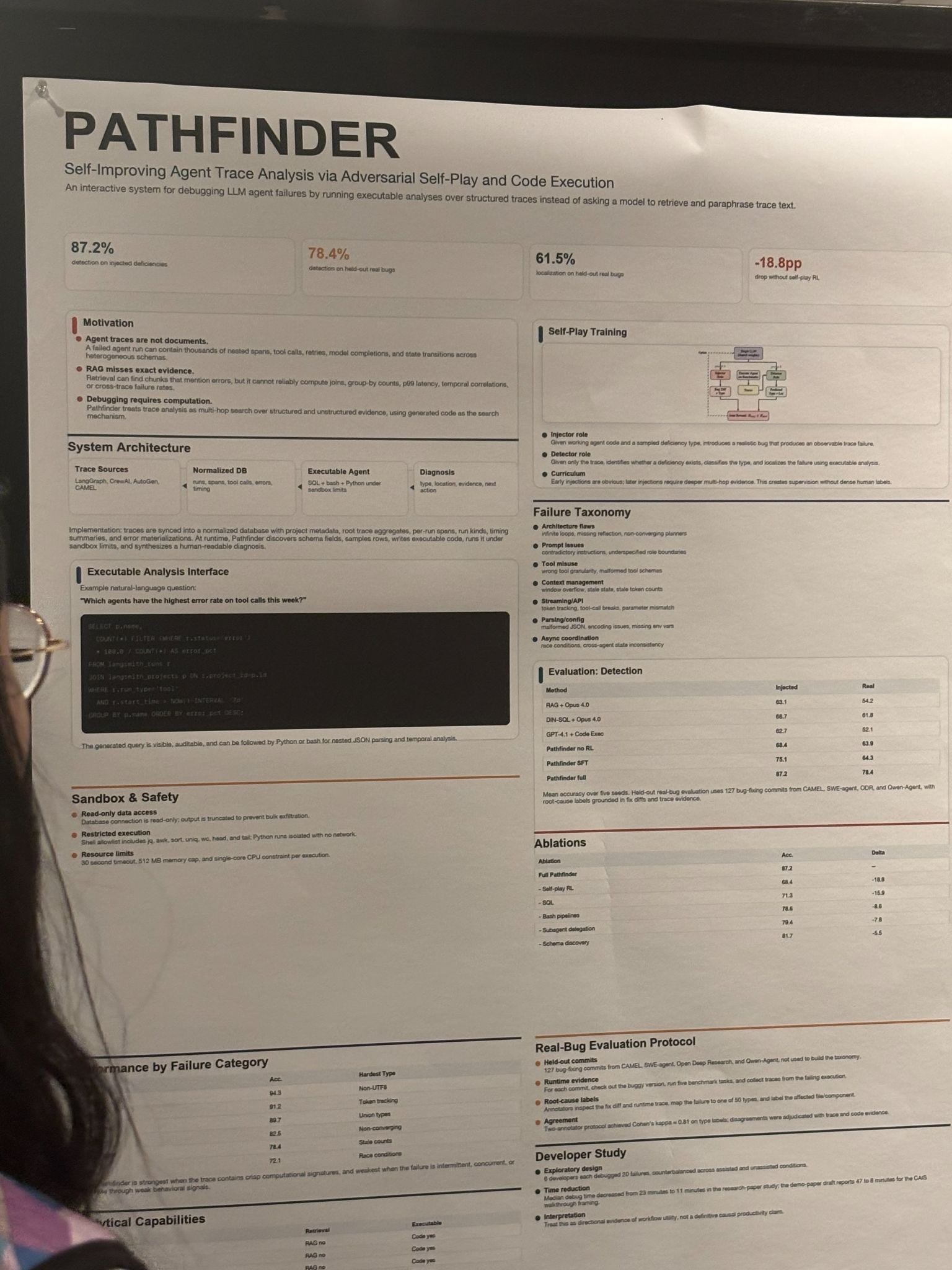
Pathfinder pointed to a structural problem: RAG cannot reliably debug agent traces because debugging requires computation (joins, aggregations, temporal correlations), not retrieval. You cannot find out why an agent failed by looking up the closest paragraph. You have to run code against the trace. Their executable analysis interface reached 87.2% accuracy on injected failure detection. Without the self-play training component, 68.4%.
There is no production-grade evaluation stack for agentic systems that isn't either hand-rolled or academic in maturity. The company that builds this, domain-specific, trace-based, executable rather than LLM-as-judge, is building infrastructure that every agent deployment needs and almost nobody has. Benchmark quality is becoming a product moat.

But the measurement problem is really a data problem in disguise. One of the sharpest framings came from the Supporting Our AI Overlords workshop, where Kenny Daniel, CEO of Hyperparam, won best paper for what he called an "iceberg moment for AI data." For most AI practitioners, the real engineering challenge is no longer the model but the unexamined mountain of data beneath it, where failures hide and current tools can't reach.
The Cost Structure Is Surprising Everyone
Most discussions about AI cost focus on tokens. Token costs are falling. Data costs aren’t: storage, query execution, data movement, latency. As agent activity increases, the number of database operations explodes. Instead of one human issuing one query, an agent generating a single answer might run dozens of queries to get there.
Aaron Katz from ClickHouse put numbers on it. His company’s internal Claude spend went from $20K in December to $300K in April. That’s not a token story. It’s a workload story. The PC created spreadsheets. The internet created web traffic. Mobile created app traffic. Agents are creating a new category of machine-generated operational activity, and infrastructure pricing models weren’t built for it.
Snowflake, Datadog, Splunk: all built excellent products for a world where humans sat between the system and the query. That world is ending. Repricing their core product to serve agent workloads means cannibalizing the revenue model that got them there. The incumbents who don’t move fast enough won’t be beaten by a better version of themselves. They’ll be replaced by companies that started from different assumptions.
Nikita Shamgunov from Neon: 13 million Postgres instances per day, spun up and down by agents provisioning their own environments. Checkpoint-restore, branch-clone, serverless-by-default, minimal precise APIs. Those aren’t features you add to an existing architecture. They require starting from a different question: what does infrastructure look like if the primary user is never a human?

Agents Are Starting to Choose Their Own Infrastructure
Katz described something that happened at Anthropic. An engineer asked Claude what observability backend to use. Claude recommended ClickHouse. The engineer migrated. That migration became a case study, which was documented, which probably increased the probability that Claude would recommend ClickHouse again the next time someone asked. An agent participated in infrastructure selection, and that selection fed back into the training data that will shape future selections.
The same pattern shows up in the research. Coding agents perform well in domains with abundant open-source history and established documentation, and struggle where there isn’t. The training data shapes the recommendation. The recommendation shapes adoption. Adoption shapes the next round of training data.
Which companies are building the knowledge base from which future agents will make decisions?
I haven’t seen that question asked clearly yet, and I think it matters more than most people realize. When an agent selects infrastructure, it isn’t reading a blog post. It’s pattern-matching against everything absorbed during training: documentation quality, GitHub activity, community presence, published benchmarks, technical writing by practitioners. The companies investing in this surface area today are building a recommendation moat that will compound in ways that are hard to observe until they become very hard to reverse.
ClickHouse appears to understand this. Their open-source community, published benchmarks, and technical documentation aren’t just developer relations. They are, potentially, the inputs that cause the next generation of agents to recommend them to the next generation of engineers who never read a comparison post.

The Future Might Look Like Marin
Percy Liang coined the term “foundation models.” He built HELM. He runs Marin, the open lab at Stanford where every experiment (including the failed ones) is live on GitHub. He distinguishes what Marin does as “open development,” separate from open-weight (you get the model but not the process) and open-source (you get the code but not the science). Open development means the research itself is visible: preregistered predictions, public training runs, transparent dead ends.
Before their last training run finished, the Marin team published a loss prediction on GitHub, then waited. They landed within 0.005 of the predicted number. That’s extrapolating 300x beyond their calibration runs. In a field where people report results after the fact, committing a prediction in public before the run is a different kind of claim.
Percy’s historical argument: AI in 2026 is where software was in 1999. After the closed period had established commercial value, but before the open ecosystem had proven it could match closed quality for most use cases. The Chinese open model ecosystem is moving faster than most Western observers credit.
That same openness is what feeds the agent recommendation loop. Genuinely open models, research visible, process documented, benchmarks published, are building the knowledge base that future agents will draw on. Not because of marketing. Because the evidence exists in the training data.
I’ve invested in open source before (Hyperparam, Paperclip, Inngest, spaCy, Budibase, Lago, Charm, and others). The pattern I look for isn’t openness as ideology but openness as distribution. When the community does your R&D, your feedback loops, and your evangelism simultaneously, that’s a different kind of defensibility than a closed API. Whether Marin gets there in two years or five, the Linux comparison is the closest precedent I know.

What I’m Taking Away
Researchers working on governance, evaluation, databases, observability, and open development were all wrestling with the same problem at CAIS. They just came at it from different angles.
The models are no longer the hard part.
The hard part is everything that happens after the model produces an answer. Can you trust it? Can you explain it? Can you audit it? Can you afford it? Can you measure it? Can you stop it from doing something you didn’t intend?
That’s a different problem than the one the industry spent the last three years on. Proving agents could do useful work. That’s mostly done. Building the infrastructure that lets everyone else depend on them. That’s what’s next.
At Motive Force, I’ve written that great software succeeds when it absorbs complexity rather than exposing it. That pressure is now landing on the agent stack.
If you’re building evaluation infrastructure, context management, agent governance, the database and execution layer for agent workloads, or the knowledge infrastructure that agents will draw on when making decisions, I’d like to talk.
Oana Olteanu is the founder and GP of Motive Force, an early-stage venture firm investing in Beautiful Software at pre-seed and seed.
oana@motiveforce.ai
The procedural compliance point hits close to home. At https://getechostack.com, we evaluate business signals across calls, forms, tickets, and emails, and the lesson we keep relearning is that output correctness is the wrong success metric. A call can end with a booked meeting and still have skipped qualification steps, missed escalation signals, or fired the wrong downstream action. Nobody catches it without trace-level auditing.
Our answer was manifest-driven evaluation: explicit criteria defined once, applied deterministically across every channel. It's not just about getting a decision. It's about whether the agent reached that decision through the path you specified, with the constraints you set honored throughout.
Your framing of governance as org chart design is exactly right. What we've ended up building is effectively a compliance layer on top of evaluation: playbook enforcement, structured outcome verification, audit trails. Not because we planned for it, but because production deployments demanded it.
The agent recommendation loop is the part I hadn't fully articulated before. Worth thinking hard about for anyone building infrastructure in this space.
Great write up of the conference! Appreciate the shout-out to Hyperparam