
The End of the Prompt: Building Voice Systems, Not Voice Apps
Notes from Pipecat's November 2025 Voice AI Meetup in San Francisco


Voice agents today are no longer just wrappers around models. They’re systems.
Systems that loop, call tools, pass memory, compress context, coordinate agents, and handle long-running tasks.
The next generation of voice isn’t just about naturalness or response quality. It’s about designing architectures that can support real-time, interactive, multi-turn orchestration. That means voice agents are increasingly looking less like interfaces and more like mini operating systems.
I’ve been watching this evolution as both a builder and an investor:
First with SAP Hybris, working on Alexa/Google Home integrations where “voice” meant wrestling with messy enterprise middleware and inventory APIs.
Now as a VC, investing in voice companies like Observe.AI, Ultravox, and OfOne, while cheering on builders like Kwindla and Nina at Pipecat and Scott at Deepgram.
Last week’s Voice AI Meetup in SF was a visceral reminder of how fast this field is moving. And how much of it still comes down to the people. Founders, engineers, model builders, infra nerds, product dreamers. On a random Wednesday night, I got to rub elbows with many of them.
Also: if you know the designer behind the Pipecat t-shirt (the loud one with neon cats in a Warhol grid), please tell them I LOVE it. Instant classic.
The Architecture Evolution
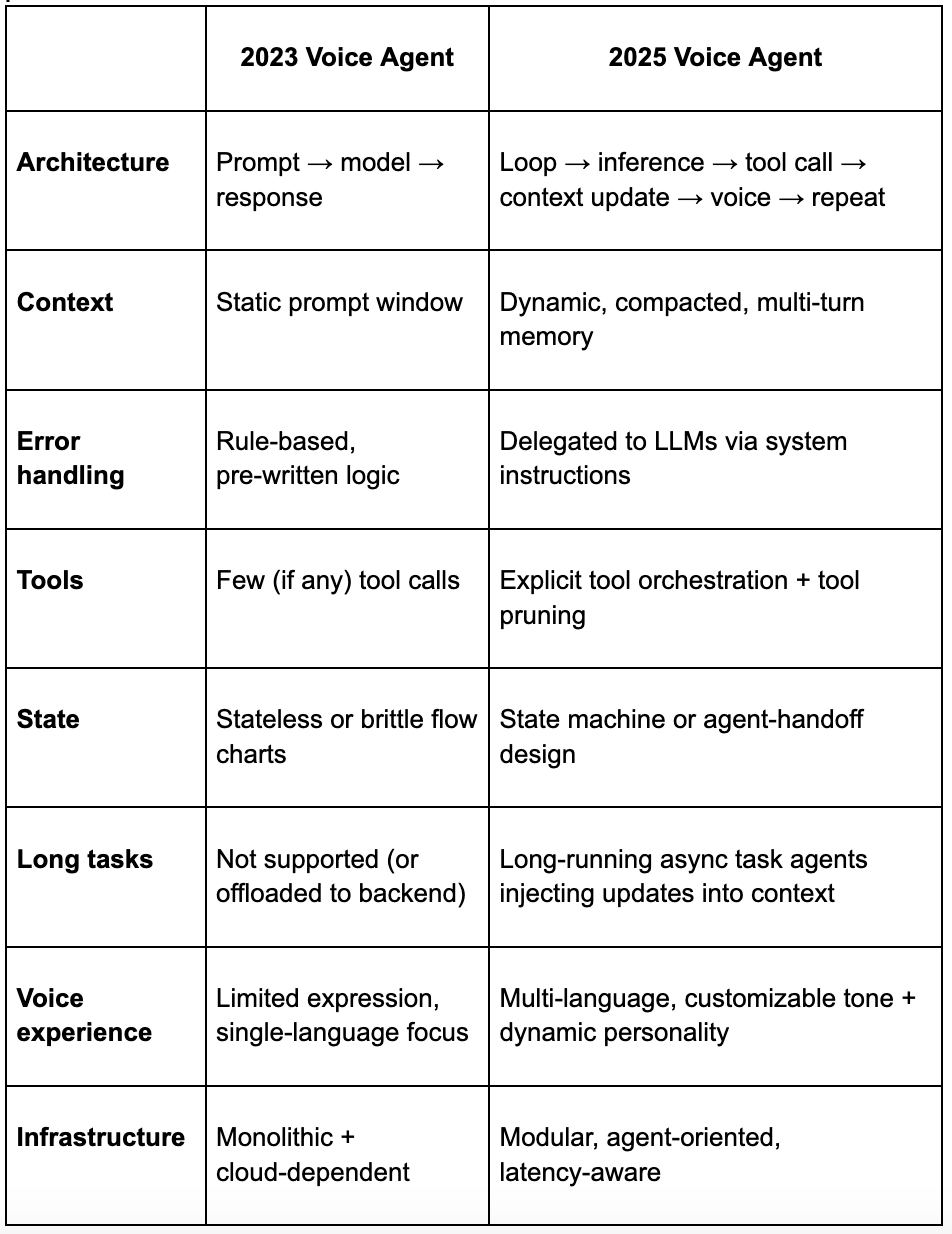
The Core Insight: Everything is a Loop + Inference + Tool Calls
Kwindla Kramer from Pipecat laid it out plainly during his talk about their voice game Gradient Bang: a voice agent isn’t just “speech in → model → speech out.” It’s fundamentally a loop: user voice input → inference → tool calls → context update → voice output → (repeat).
The loop must be non-blocking so the UI stays snappy, and capable of handing over to long-running tasks without losing context.
They flagged three core engineering challenges:
Prompt/context engineering still matters. Models don’t “do the right thing” by default. You still need to wrestle them into submission.
Coordination of sub-agents is messy. You’re now orchestrating multiple models, tools, workflows. It’s like herding cats, except the cats are on fire and also doing calculus.
Termination/latency/debugging become deeply painful. When loops can spawn sub-agents, audit trails disappear into the ether.
Nine Patterns That Actually Matter
What made the meetup particularly valuable was Kwindla walking through nine specific agentic patterns. They’ve discovered these building voice agents for enterprise use cases, and have been exploring them more in the open-ended Gradient Bang project. For engineers building voice systems, these are gold:
Pattern 1: State Machines
Build voice agents with state machines where each conversation state has its own system instruction, tool list, and context compression strategy. State transitions are opportunities to rewrite the entire LLM input. This approach measurably improves success rates. You can build this from scratch or use libraries like Pipecat Flows.
Pattern 2: Agent Handoff
Similar to state machines but conceptually different: instead of rewriting the LLM input, you transfer the conversation to another agent process. During handoff, you can operate on previous state and pass state forward. The tricky part is defining the handoff context and instructions. Choose whichever mental model (state machine vs agent handoff) maps better to your brain.
Pattern 3: Parallel Inference for Context Compaction
Run two LLMs in parallel sharing the same conversation context but with different system instructions. Use a gate (rule-based trigger) to compact conversation when context reaches certain thresholds. The compactor LLM transforms the full conversation into shorter context, replacing it in real-time.
Pattern 4: UI Driver Agent
Another parallel inference pattern: run a UI state LLM alongside your conversation LLM. The UI agent receives full conversation context each turn and outputs structured JSON that drives client-side UI. Use a “no-op” tool call or gate to handle turns where UI shouldn’t change.
Pattern 5: Long-Running Asynchronous Tasks
Make a tool call that starts a task, then returns immediately with a static success response and task ID. The long-running task then shoves context into the voice agent as XML-wrapped events. This feels like a kludge with today’s LLMs (working against the grain), but it’s so valuable that teams do it anyway.
Illustrative example
User: “Monitor the tech news sites for any announcements on new AI models”
Model: tool_call (start_monitoring_task(...))
Tool Response: { task_id: “task_123”, status: “running” }
Model: “I’m monitoring tech news sites for AI model announcements”
// 5 minutes later, task injects event into conversation:
<event task_id=”task_123” name=”news.found”>
Source: TechCrunch
Title: OpenAI announces GPT-5
Summary: New model with 10x parameters
</event>
Model: “Just spotted something! OpenAI announced GPT-5 on TechCrunch with 10x the parameters of GPT-4”
//10 minutes later:
<event task_id=”task_123” name=”news.update”>
Source: The Verge
Title: Google responses with Gemini Ultra 2
Summary: Multimodal model beating benchmarks
</event>
Model: “Google just responded! The Verge is reporting Gemini Ultra 2 with benchmark-beating multimodal capabilities”Kwindla’s insight: “We’re abusing the tool call and tool response mechanism. We’re trying to figure out how to wrap events in user tag messages for the multi-turn context. It works. But if you build a lot of stuff with LLMs you develop intuitions about when you’re working with the grain of the model and when you’re working across the grain. This very much feels like working across the grain.”
Pattern 6: Sandboxed Long-Running Tasks
Same as Pattern 5 but run tasks in sandbox environments. Use network protocols (MCP or others) to decouple infrastructure, make applications extensible, or execute code safely.
Pattern 7: Library Agent
Use natural language capabilities of two different LLMs for sophisticated content lookup. Voice LLM generates queries using conversation context, then sends to another LLM with larger world context (massive system instructions, vector databases, backend systems). This separation of concerns with natural language drivers on both ends is powerful.
Pattern 8: History Agent
Similar to library agent but for querying domain-specific structured data (SQL databases, logs). The query LLM can loop through tool calls or write code. Trade-off: return structured data (more flexible but token-heavy) or natural language summary (token-efficient but less flexible).
Pattern 9: Use Audio Tokens Once
For audio-native LLMs like Gemini 2.5 Flash: feed audio directly for conversation inference (no separate transcription model), but run parallel transcription pipeline. Replace audio tokens with text after each turn because audio tokens degrade performance faster than text. Doesn’t matter if you miss a turn occasionally.
Technical Insights from the Panel
On Model Training and Multi-Turn Performance
Arjun from Cartesia made a fascinating point about architectures. Transformers scale quadratically in memory and speed, which is why longer context makes models slower. State space models (which Cartesia pioneered) are inspired by human memory: a fixed amount of space where you’re constantly recalling and reconstructing.
“Historically models have operated in this way where it’s in the cloud, you send context to it, it returns something and it completely forgets. That’s not how the world works. Whether it’s what we’re talking about now versus yesterday or 10 years ago, all of that influences how I’m talking today.”
On Error Handling: Just Throw It at the Model
John from Google had my favorite insight of the night. Instead of writing elaborate error handling code, just throw errors to the LLM:
// Old way: Precise error typing
try:
do_some_stuff()
catch FancyException e:
handle_this_error(e)
catch BanalException f:
handle_that_too(f)
// New way: Let the LLM figure it out
{ “model”: tool_result<”natural language error description”>}
{ “model”: “Hey, so this thing happened...” }The LLM has the system instruction, conversation context, and can infer user intent. It’s actually better at error handling than your code could ever be.
On Tools and Constraints
John’s advice on tools was spot-on: “The tool space has to be orthogonal. If you have contraindicated tools, if you have a ton of tools, it’s just gonna be confused.”
They discovered in Gradient Bang that they hit the tools limit before hitting context coherence limits. Too many tools = hallucination risk. The solution? Trim your tools list aggressively. Give the model breathing room.
He also shared this gem about prompting: “These models are very rational and very childlike. If you give them too many ‘do this, don’t do that’ constraints, they’ll just do something they think you want, but it’s not right.”
On Global Markets and Voice Democratization
Taruni from Hathora raised a critical point that resonates with my thesis about overlooked markets: “The English language is quite well served... but the current pricing model and types of models developed are just not conducive for innovation outside of the US.”
Arjun agreed, noting Cartesia’s Sonic 3 now supports 42+ languages and hundreds of dialects from one base model. The future of voice isn’t US-centric. Founders building for global, lower-cost regions with multi-language support may win the next wave.
What This Means for Founders
If you’re building in voice or conversational interfaces: Don’t start by picking a TTS or ASR model. Start by mapping the loop architecture. What are the states? What are the transitions? What sub-agents will you spawn?
Pay attention to tool design. A minimal, orthogonal tool set beats a sprawling “everything API” every time. Every. Single. Time.
Latency and termination = user experience. A beautiful model with 1.2 second delay will feel sluggish. Ensure your architecture supports fast turnaround, text token summarization (especially replacing audio tokens with text after transcription).
For investor-facing portfolios: Voice AI is increasingly less about model accuracy and more about system orchestration. Ask founders: how are you managing context, memory, loop termination, and tool orchestration? If they can’t answer clearly, run.
Consider global and multiplayer dimensions. Many voice stacks are US/English centric. Emerging founders who enable voice in other languages, lower cost regions, multiplayer settings and low latency may win the next wave.
The Bigger Picture
What struck me most wasn’t any single pattern or model improvement. It was the realization that we’re building something fundamentally new. Not voice interfaces. Voice operating systems.
As Kwindla put it: “Software is going to look very different once we all figure this stuff out.”
We’re moving from programming UIs to just throwing structured data across the wire and letting models figure out how to render it. We’re replacing error handling with natural language descriptions. We’re building systems where the agent loop IS the product.
This isn’t incremental improvement. It’s a phase change in how we build software.
The patterns Kwindla shared aren’t just clever hacks. They’re the early design patterns of a new computing paradigm. State machines, agent handoffs, parallel inference, long-running tasks producing XML events. This is what building voice systems looks like in 2025.
And here’s what excites me most as an investor: the best builders aren’t waiting for models to get better. They’re architecting around current limitations, discovering patterns that will define how we build for the next decade.
If you’re building in voice (infrastructure, UX, or model layers), find me. I want to meet you. Email me at oana@motiveforce.ai
Special thanks to Kwindla for sharing the patterns that are actually moving the needle, and to Jeff for pushing me to include the technical meat that engineers actually care about.
More essays: What Makes 5% of AI Agents Actually Work in Production?, Agentic systems: panning for gold, Semantic layers, Fine Tuning, Founder Mental Software, Normalizing the Founder Journey, AI Engineer World’s Fair 2025 - Field Notes